

Zahlreiche Unternehmen nutzen bereits Data Science und Machine Learning (ML) als Teilbereich der Künstlichen Intelligenz (KI), um ihre Wettbewerbsposition zu stärken. Trotz der strategischen Neuausrichtung vieler Firmen hin zu einer datengetriebenen Organisation gelingt es häufig noch nicht, einen messbaren Wert aus Data-Science-, Analytics- und ML-Use-Cases zu generieren. Im Gegenteil: Viele Analytics- und ML-Use-Cases verharren in der Entwicklungsphase und werden nicht in einer Produktionsumgebung eingesetzt und betrieben – damit können wertvolle und zum Teil aufwendig entwickelte Algorithmen, Modelle und Erkenntnisse nicht in den Kernprozessen der Organisation genutzt werden.
Studien [Alg21] zufolge fehlt es in Unternehmen häufig noch an der erforderlichen Expertise, um ihre strategischen ML-Ziele erreichen zu können und einen geschäftlichen Nutzen aus ML-Projekten zu generieren. Vielmehr stellt die Entwicklung solcher Modelle und deren Überführung in die Praxis eine komplexe Aufgabe dar. Obwohl die Budgets für KI steigen, melden 64 Prozent der Unternehmen [Alg 21], dass es über einen Monat dauert, bis ein bereits fertig entwickeltes Modell integriert und produktiv genutzt werden kann. Grund dafür ist der hohe Grad an Komplexität, den der Betrieb dieser Modelle in den bestehenden IT-Prozessen darstellt. Dazu gehören neben der Datenaufbereitung und der deskriptiven Datenanalyse auch weitere Aspekte wie die Dokumentation und Speicherung von Experimenten und Modellen, das Testen von Codes und Modellen sowie das Monitoring laufender ML-Modelle in der Produktion.
Wie unterstützt MLOps bei der Erstellung anpassungsfähiger Machine-Learning-Modelle?
Machine Learning Operations (kurz: MLOps) bietet Unternehmen ein verlässliches Framework aus Prozessen und Technologien, um die Entwicklung, das Deployment und den Betrieb eines ML-Modells zu vereinfachen und zu operationalisieren (siehe Abbildung 1). MLOps setzt sich aus Data Operations (DataOps), Model Operations (ModelOps) sowie Development Operations (DevOps) zusammen. Während DevOps Prinzipien und Methoden zur Optimierung und Verkürzung des Entwicklungsprozesses (Dev) und des Betriebs (Ops) bezeichnet, fokussiert DataOps auf den Prozess und Betrieb von Datenprozessierungsschritten sowie auf Anwendungsfälle rund um Datenanalysen und ModelOps auf den Prozess und Betrieb analytischer Modelle. MLOps erweitert diese Konzepte um ML-spezifische Aspekte, wie die automatische Messung von Performance-Metriken eines Modells, Vergleiche zwischen Modellen sowie automatische Datenanalysen, um festzustellen, ob die Genauigkeit eines Modells nachgelassen hat.
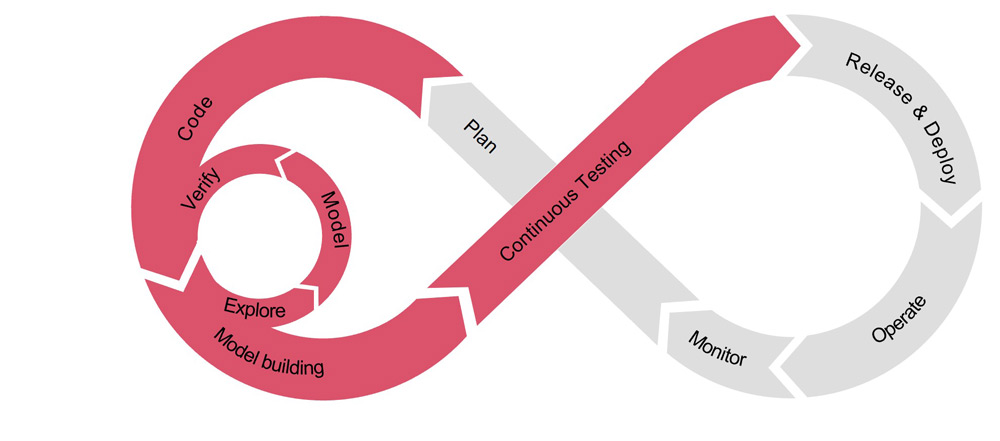
Abb. 1: Schematische Darstellung des Entwicklungsprozesses von ML-Modellen im MLOps-Framework (eigene Darstellung, in Anlehnung an [Inn22])
Ein weiterer Kernpunkt von MLOps ist die Einbindung und Ermöglichung von AI Governance. AI Governance beschreibt alle Prozesse, Strukturen und Methoden, mit denen ein Unternehmen Transparenz über seine KI-Modelle und deren Metadaten schafft, um eine faire sowie ethisch und regulatorisch unbedenkliche Nutzung von KI zu ermöglichen [Bas20]. Anhand dessen können sich Data Scientists und Data Engineers auf die Entwicklung der Modelle konzentrieren, deren Qualität sicherstellen und durch Dokumentation, Replizierbarkeit und Übersichtlichkeit eine transparente AI Governance gewährleisten. Dadurch sind Unternehmen in der Lage, ihre Use-Cases schneller, sicherer und mit weniger Aufwand zu realisieren sowie zusätzliche Ressourcen für neue Projekte freizulegen.
MLOps für Modellentwicklung und AI Governance
In Data-Science-Projekten arbeiten eine Vielzahl von Spezialisten wie Data Scientists, Data Engineers und DevOps Engineers zusammen. Je größer die Teams werden, desto schwieriger wird es, den Überblick zu behalten, an welchen Code-Abschnitten Änderungen vorgenommen wurden, welcher der neueste Stand des Quellcodes und wie genau die Aufgabenverteilung ist. In diesen Fällen bietet MLOps bewährte Techniken wie Code-Versionierung, Repositories und Projektmanagement-Methoden wie Kanban und Scrum.
Anders als in der klassischen Softwareentwicklung ist im Bereich Data Science nicht nur die Replizierbarkeit und Versionierung von Code entscheidend, sondern auch die verwendeten Datensätze und Metadaten der Experimente. Für die Versionierung von Datensätzen und die Aufbereitung der Daten nutzt MLOps die Methoden von DataOps. Demnach werden sämtliche verwendeten Datensätze (Training, Validierung und Test), die sowohl zu Entwicklungszwecken als auch zur Erstellung des finalen Modells in der Produktion verwendet werden, registriert. Alle Schritte, die zur Datenaufbereitung notwendig sind, werden in einer replizierbaren Pipeline abgebildet. Eine Pipeline ist ein ausführbares Skript, in dem alle benötigten Schritte eines Prozesses definiert sind, zum Beispiel um eben die Datenaufbereitung automatisiert zu starten. Das umfasst unter anderem die Überprüfung der Datenqualität sowie das Anreichern, Transformieren und Normalisieren von Datensätzen bis hin zur Feature-Selektion.
Die Versionierung der ML-Modelle und verwendeten Daten ist ein wichtiger Bestandteil des MLOps-Prozesses, um Transparenz über die durchgeführten ML-Experimente zu wahren, und kann im Rahmen von Unternehmens- als auch regulatorischen Vorschriften zwingend erforderlich sein. Dies unterstützt auch die Umsetzung einer AI Governance, indem eine transparente Dokumentation über Modellversionen und zugehörige Trainingsdaten hergestellt wird und Governance-Kriterien auf diese Weise automatisiert überprüft werden können.
Im Gegensatz zum traditionellen Softwareentwicklungsprozess können bei der ML-Entwicklung mehrere Experimente zum Modelltraining parallel durchgeführt werden, bevor abschließend entschieden wird, welches Modell in die Produktion überführt werden soll. Beim Tracking, der Überprüfung und dem Management von ML-Modellen hilft eine ML-Lifecycle-Plattform wie zum Beispiel MLFLow. Mit einer solchen Plattform lassen sich alle Modellparameter, die Herkunft des Quellcodes und die Performance-Metriken eines Trainingszyklus protokollieren. Performance-Metriken im ML-Kontext werden verwendet, um die Güte des Modells zu messen und die ML-Modelle nach diesen Metriken zu optimieren. Dazu gehören beispielsweise Metriken wie der Anteil von korrekten Vorhersagen an allen getroffenen Vorhersagen sowie Falsch-Negativ- oder Falsch-Positiv-Raten [Baj22]. Des Weiteren dient eine ML-Lifecycle-Plattform als Modellregister, um die vorhandenen Modelle zu „versionieren“ und zu registrieren. Zudem unterstützt sie maßgeblich bei der Überführung des Modells von der Entwicklungsumgebung in die Produktion. So kann der gesamte Lebenszyklus eines ML-Projekts und seiner Bestandteile besser verwaltet werden (siehe Abbildung 2).
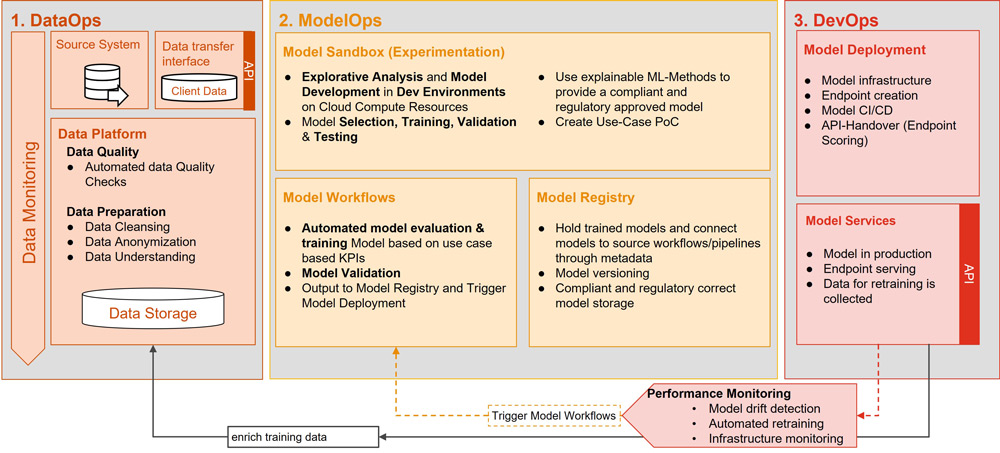
Abb. 2: Schematische Darstellung des Zusammenspiels von DataOps, ModelOps und DevOps
Continuous Monitoring und Continuous Training
Anders als bei herkömmlicher Software ändert sich die Qualität und das Ergebnis eines ML-Modells mit den einfließenden Daten, die für die Vorhersagen verwendet werden. Während ein Modell ursprünglich auf einem konstanten Datensatz trainiert wird, analysiert und nutzt das trainierte Modell im produktiven Betrieb Daten zur Vorhersage, die sich mit der Zeit verändern. Diesen Anforderungen sollte das Monitoring gerecht werden.
Beispielsweise könnte ein ML-Modell die Nachfrage unterschiedlicher Personengruppen für ein neues Produkt vorhersagen. Mit der Zeit gewinnt das Produkt an Bekanntheit und neue Personengruppen fragen das bisherige Nischenprodukt an. Da das ML-Modell allerdings auf Charakteristika der ursprünglichen Zielgruppe trainiert wurde, kann es die neuen Personengruppen nicht einschätzen und verfehlt seine Performance-Anforderung.
Dieses Phänomen bezeichnet man als Data Drift. Damit Unternehmen hiervon nicht überrascht werden, sollten die Performance-Güte des ML-Modells und die Charakteristika der eingehenden Daten auch nach Inbetriebnahme des Modells kontinuierlich geprüft und bewertet und gegebenenfalls ein sogenanntes Retraining des Modells mit den neuen Daten initiiert werden. Ohne ein Retraining kann das ML-Modell einen Performance-Verlust erleiden.
Eine weitere Quelle von Performance-Verlusten im ML-Modellbetrieb ist der sogenannte Concept Drift. Im Gegensatz zu Data Drift spielt hier nicht die Beschaffenheit und Verteilung der Input-Daten eine Rolle, sondern die des Outputs, mit dem die Performance gemessen wird. Concept Drift tritt ein, wenn sich die zu messende Variable verändert. Das kann beispielsweise geschehen, wenn ein Unternehmen ein ML-Modell zur Risikoeinstufung betreibt und deren Definition ändert. Während hier die tatsächlichen Risikofaktoren, also die Input-Daten, unverändert bleiben, ändert sich die Auswertung dieser Faktoren. Wird das ML-Modell nicht mit den neuen Definitionen neu konfiguriert und trainiert, verringert sich automatisch seine Genauigkeit.
Continuous Integration und Continuous Delivery
Wie in der herkömmlichen Softwareentwicklung lassen sich ML-Modelle durch Continuous-Integration- und Continuous-Delivery-Pipelines (CI/ CD) schneller produktiv nutzen und kontinuierlich verbessern. Continuous Integration bezeichnet das Integrieren von neuen Quellcodeänderungen in den zentralen Projektquellcode, wobei mit automatisierten Tests die Qualität der Änderungen sichergestellt wird. Continuous Delivery hingegen beschreibt das anschließende automatisierte Deployment von Änderungen auf Test- und Produktivumgebungen. Diese Pipelines umfassen das Testen und Ausführen aller Schritte im Lebenszyklus eines ML-Modells [GML20] – von der Aufbereitung und Zusammenstellung der benötigten Datensätze bis hin zum Training und der Bereitstellung des finalen Modells sowie der dazugehörigen Versionierung.
Mit Hilfe der CI-/CD-Pipelines kann ein aktualisiertes ML-Modell zunächst auf Testumgebungen eingesetzt werden, um die Verträglichkeit mit dem Produktivsystem zu sichern. Außerdem werden automatisierte Tests ausgeführt, deren Ergebnisse mit gesetzten Schwellenwerten verglichen oder über manuelle Genehmigungsschritte als erfolgreich deklariert werden können, um letztendlich das finale Deployment in das Produktivsystem auszulösen. Hier werden die Qualität und Integrationsfähigkeit des Quellcodes und des Modells geprüft, die Qualität und Abweichung der Daten (zum Beispiel Data Drift) untersucht sowie die Performance neuer Modelle verglichen. Ein Modell, das zwar alle technischen Anforderungen des produktiven Systems erfüllt, aber eine schlechtere Performance hat, liefert keinen Mehrwert.
Zudem sollten aussagekräftige Performance-Metriken frühzeitig für das Modell definiert werden. Wesentliche Faktoren sind hier beispielsweise die statistische Verteilung von Input- und Output-Daten sowie die Auswirkungen eines falschen Outputs. Bei einem binären Klassifizierungsproblem könnte eine falsch-negative Klassifizierung kaum Auswirkungen haben, während eine falsch-positive Klassifizierung zu hohen Kosten und zahlreichen weiteren Prozessschritten auf Unternehmensseite führen könnte. Um solche Probleme zu vermeiden, sollte die Auswahl der Performance-Metriken sorgfältig durchdacht und analysiert werden.
Wie kann die Architektur einer Analytics-Plattform aussehen?
MLOps-Prozesse und die Nutzung von ML-Modellen stellen enorme Anforderungen an die Hardware-Infrastruktur von Unternehmen. Die Mengen an strukturierten und unstrukturierten Daten wachsen stetig, die Anforderungen an die Rechenleistung wechseln bei Retrainings stark und Modellergebnisse werden häufig in Echtzeit angefordert.
Wenn Unternehmen eine On-Premises-Lösung bevorzugen, also die Nutzung lokaler Software auf hauseigenen Servern, kann auch eine solche Infrastruktur den Anforderungen gerecht werden. Cloud-Technologien punkten hier allerdings vor allem durch das leichtere Aufsetzen einer skalierbaren Infrastruktur. Diese reagiert dynamisch auf wechselnde Anforderungen, wodurch sich teure Investitionen in die eigene Hardware vermeiden lassen. Viele Cloud-Anbieter stellen neben Tools, die die Elemente eines MLOps-Prozesses abdecken, auch umfassende Analytics-Plattformen zur Verfügung, die die Anwendung von Machine Learning für Unternehmen stark vereinfachen.
Abbildung 3 beschreibt eine mögliche Implementierung von MLOps auf der Microsoft Azure Cloud. Eine solche Architektur ist auch auf anderen Cloud-Plattformen wie Amazon Web Services und der Google-Cloud-Plattform möglich, insbesondere durch Nutzung von Cloud-Plattform-unabhängigen Tools und Plattformen wie Databricks und MLFLow. Anstelle der Einbindung von Databricks als Entwicklungs- und Modelltrainingsplattform können auch alternative Entwicklungsumgebungen – wie im Beispiel Azure die Notebooks und Rechencluster innerhalb von Azure Machine Learning [Mic21] – genutzt und gegebenenfalls durch eine Einbindung von Azure Synapse Analytics erweitert werden. Da in diesem Architekturbeispiel jedoch die Cloud-unabhängige Implementierung von MLOps im Vordergrund steht, bietet sich insbesondere Databricks an, da es mit allen großen Cloud-Anbietern integriert ist. Die Entscheidung über die einzelnen Komponenten ist letztendlich jedoch eine Frage der Anwendungsfälle, der Arbeitsweise von Teams und persönlicher Präferenzen.
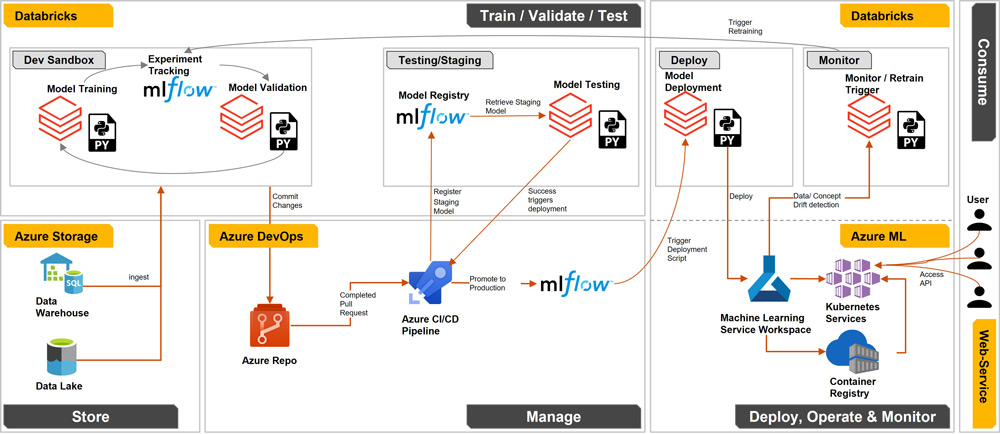
Abb. 3: MLOps-Architektur auf der Microsoft Azure Cloud
Entwicklung, Deployment und Betrieb von ML-Modellen auf der Zielarchitektur
Die Entwicklung eines ML-Modells beginnt nach dem Importieren der Daten aus einem Data Warehouse oder einem Data Lake mit einem iterativen Prozess aus Datenexploration, Modelltraining und Modellvalidierung auf Python-, R- oder Spark-Notebooks in Databricks. Dabei werden alle Experimentergebnisse, Modellparameter und Metadaten in MLFLow gespeichert.
Sobald der Data Scientist mit dem Ergebnis des Modelltrainings zufrieden ist, fügt er die angepassten Trainings-Notebooks dem Code-Repository über einen Commit hinzu. Ein anschließender erfolgreicher Pull Request der Änderungen startet die CI-/CD-Pipeline. Die Pipeline testet zunächst die Performance des Modells gegen einen Testdatensatz und startet im nächsten Schritt das Deployment des ML-Modells.
Während Databricks als integrierte Entwicklungsumgebung für das Trainieren, Testen und Retraining von Modellen dient, bietet Azure Machine Learning die Funktionalität, ein trainiertes Modell über eine API abzufragen sowie den Health Status der API und einen möglichen Data und Concept Drift zu überwachen. Das Modell und seine API werden in einem Kubernetes-Container bereitgestellt, wodurch das ML-Modell leicht skalierbar ist. Bei einer erhöhten Nachfrage an das Modell skaliert das Kubernetes-Cluster seine Ressourcen hoch und kann dadurch ein kontinuierliches Echtzeit-Scoring sicherstellen.
Über den Azure ML Data Drift Monitor kann ein automatisiertes Retraining des Modells mit neuen Datensätzen ausgelöst werden, sobald die Performance des Modells oder die Abweichungen der Input-Daten eine vordefinierte Schwelle überschreiten. In diesem Fall wird der gesamte Prozess wie oben beschrieben erneut automatisiert durchlaufen und ermöglicht mit möglichst geringem Aufwand, einen Überblick über die Modell-Performance zu behalten und diese kontinuierlich aufrechtzuerhalten.
Warum Sie MLOps in Ihrem Unternehmen einführen sollten
MLOps liefert einen verlässlichen Rahmen aus Prozessen und Tools, mit dem Unternehmen die Geschwindigkeit, Effizienz und Qualität ihrer ML-Modelle steigern können. Sie können so zeitnah geschäftlichen Nutzen aus maschinellem Lernen realisieren und durch Automatisierung wertvolle Ressourcen sparen. CI-/CD-Pipelines ermöglichen ein schnelles Deployment und regelmäßige Updates. Ein automatisches Monitoring der produktiven Modelle verringert die Notwendigkeit manueller Kontrollen durch Data Scientists und Engineers, die stattdessen zusätzliche Use-Cases entwickeln können. MLOps-Pipelines gewährleisten mit Hilfe von automatisierten Benachrichtigungen und möglichen manuellen Genehmigungsschritten Qualitätskontrollen vor neuen Releases und ermöglichen eine effiziente Versionierung von Datensätzen, Modellen und Experimenten. Die Dokumentation, Speicherung und Transparenz der Modelle in allen Entwicklungsphasen macht sie replizierbar und hilft, regulatorische Dokumentationsanforderungen zu erfüllen.
Damit bietet MLOps Unternehmen die erforderlichen Werkzeuge, um Machine-Learning-Projekte über den gesamten Lebenszyklus begleiten und weitere ML- und Data-Science-Projekte realisieren zu können.
Weitere Informationen
[Alg21] Algorithmia Inc: 2021 Enterprise Trends in Machine Learning State of Enterprise Machine Learning. Algorithmia Inc., 2021
[Baj22] Bajaj, A.: Performance Metrics in Machine Learning (Complete Guide). 21.7.2022, https://neptune.ai/blog/performance-metrics-in-machine-learning-complete-guide, abgerufen am 23.10.2022
[Bas20] Basis AI: AI Governance: The path to responsible adoption of artificial intelligence. Basis AI 2020
[GML20] Google cloud: MLOps: Continuous delivery and automation pipelines in machine learning. 2020, https://cloud.google.com/architecture/mlops-continuous-delivery-and-automation-pipelines-in-machine-learning, abgerufen am 27.10.2022
[Inn22] INNOQ: CRISP-ML(Q). The ML Lifecycle Process. 2022, https://ml-ops.org/content/crisp-ml, abgerufen am 21.10.2022
[Mic21]Microsoft Azure: MLOps with Azure Machine Learning – Accelerating the process of building, training, and deploying models at scale. 2021, https://www.infusedinnovations.com/wp-content/uploads/2022/04/MLOps-with-Azure-Machine-Learning.pdf, abgerufen am 23.10.2022









