

Durch die teils spektakulären Erfolge von Verfahren der Künstlichen Intelligenz (KI), vor allem von lernenden neuronalen Netzen, im Bereich strategischer Spiele, der Bilderkennung und Verarbeitung natürlicher Sprache, besteht ein großes industrielles Interesse, diese auch für cyberphysische Systeme im industriellen Kontext einzusetzen. Durch den Einsatz von lernenden Algorithmen in großen softwarebasierten Systemen ergeben sich jedoch neue Anforderungen an die Absicherungsprozesse und -methoden: Die Qualität der KI-Komponenten hängt entscheidend von den verwendeten Lernverfahren und Trainingsdaten ab. Das aus einer großen Zahl von Eingaben gelernte Verhalten lässt sich nur unzureichend spezifizieren und nicht unmittelbar in einem Modell abbilden. Zudem lässt sich das Verhalten der KI-Komponenten oft nur stochastisch vorhersagen, traditionelle Sicherheitsanalysen sind daher nicht möglich.
Darüber hinaus sind neuronale Netze extrem empfindlich gegenüber Umgebungsbeziehungsweise Verteilungsveränderungen („distributional shift“), sodass spezifische Robustheitsanforderungen geprüft werden müssen, um sicherzustellen, dass diese Netze auch bei ansonsten vernachlässigbaren Änderungen der technischen und anwendungsbezogenen Rahmenbedingungen noch funktionieren. Wenn Trainingsdaten zur Laufzeit des Systems gesammelt und zum kontinuierlichen Lernen eingesetzt werden, besteht die Gefahr des „katastrophalen Vergessens“. Auch ist es häufig schwierig, die vom System gewünschten Eigenschaften in einer formalen Sprache auszudrücken, um nachzuweisen, dass diese im Lernprozess erreicht beziehungsweise beibehalten werden.
Außerdem erfordert der Einsatz von neuronalen Netzen die Berücksichtigung neuer Schwachstellen in der Informationssicherheit. Ein typisches Security-Problem ist zum Beispiel das der „adversarial examples“, bei dem gezielt Eingabedatensätze konstruiert oder manipuliert werden, die eine bereits trainierte KI zu falschen Ergebnissen führt. Ein oft zitiertes Beispiel ist hier die KI-basierte Bildverarbeitung beim autonomen Fahren, die durch Anbringen von kleinen schwarzen und weißen Streifen auf einem Stoppschild dazu gebracht werden kann, dieses falsch zu klassifizieren (siehe Abbildung 1).

Abb. 1: Originalbild und für die Klassifikation manipuliertes Bild
Im Folgenden diskutieren wir, inwieweit diese Probleme mit einem modellbasierten Ansatz gelöst werden können. Schwerpunkt dabei sind Methoden und Werkzeugen zur Analyse lernender Systeme, die neuronale Netze als wesentliche Komponenten enthalten. Folgende Technologien sind hierbei von Interesse.
Simulation von Umgebungsmodellen
Klassische Methoden des maschinellen Lernens (ML), wie etwa gewichtete Entscheidungsbäume, Bayes-Inferenz und kernbasierte Methoden, sind nur sehr begrenzt für die Verarbeitung von hochdimensionalen sensorischen Daten, zum Beispiel Kamerabildern oder Laser-Scans, geeignet. Solche Daten sind jedoch eine unumgängliche Grundlage für die autonome Entscheidungsfindung in komplexen eingebetteten Systemen. Künstliche neuronale Netzwerke können mit überwachtem (supervised) oder verstärkendem (reinforcement) Lernen durch ihre umfangreiche innere Struktur stabile Lernerfolge erzielen.
Dazu ist jedoch eine große Zahl von geeigneten Trainingsdaten erforderlich, die für industrielle Ansätze nicht immer zur Verfügung steht. Beispielweise ist es für das Erlernen einer optimalen Strategie zur Hinderniserkennung beim autonomen Fahren nicht möglich, diese Daten erst im Betrieb zu sammeln. Bei sicherheitskritischen Systemen stellt zusätzlich die Abdeckung von Randbedingungen und kritischen Situationen in den Test- und Trainingsdaten ein systematisches Problem dar.
Für das Anlernen der KI-Algorithmen können umfangreiche Datensätze modellbasiert erzeugt werden, indem Modelle der Umgebung des KI-Systems in einer Simulation ausgeführt werden. Im Beispiel der kamerabasierten Objekterkennung für autonomes Fahren könnte das Umgebungsmodell etwa Fußgänger, die unerwartet die Fahrbahn betreten, und Plastiktüten, die vom Wind aufgewirbelt werden, enthalten (siehe Abbildung 2). Auf diese Weise lassen sich verlässliche Trainingsdaten und Testdaten unter besonderer Berücksichtigung der Abdeckung kritischer Ausnahmefälle erzeugen.

Abb. 2: Simulierte Straßenszene mit Hindernis
Die Frage, wie die dafür notwendigen Simulations- und Umgebungsmodelle strukturiert sein müssen, wie sie erzeugt werden können und wie aus ihnen verlässliche Testdaten gewonnen werden können, mit denen sich die neuronalen Netze zuverlässig und systematisch trainieren lassen, ist derzeit Gegenstand intensiver Forschung.
Automatisierte Modellprüfung
Neuronale Netze können, aufgrund ihrer regulären inneren Struktur, nicht wie klassische Algorithmen modelliert und verifiziert werden. Insbesondere Verfahren, die auf der Analyse des Quelltexts beruhen (z. B. White-Box-Testen und die Verifikation eines Programms auf Basis des Quelltexts) lassen keine Rückschlüsse mehr auf die eigentliche Funktionalität einer ML-Komponente zu.
Ein vielversprechender Ansatz zur Verifikation mehrschichtiger tiefer neuronaler Netze besteht darin, das Klassifikationsverhalten als Erfüllbarkeitsproblem zu beschreiben und mit prädikatenlogischen Lösungsverfahren (sogenannten SMT-Solvern) zu lösen. Damit kann zum Beispiel das Problem der adversarial examples reduziert werden. Der Solver könnte zum Beispiel berechnen, welche Manipulationen am Bild des Stoppschildes dazu führen, dass die Klassifikation fehlschlägt.
Für KI-Systeme als Komponenten in einem Systemverbund bietet sich vor allem ein stochastisches Model-Checking an, bei dem die Entscheidungen der KI-Komponenten als Übergänge in einem Transitionssystem aufgefasst werden, die mit einer gewissen Wahrscheinlichkeit versehen sind (siehe Abbildung 3).
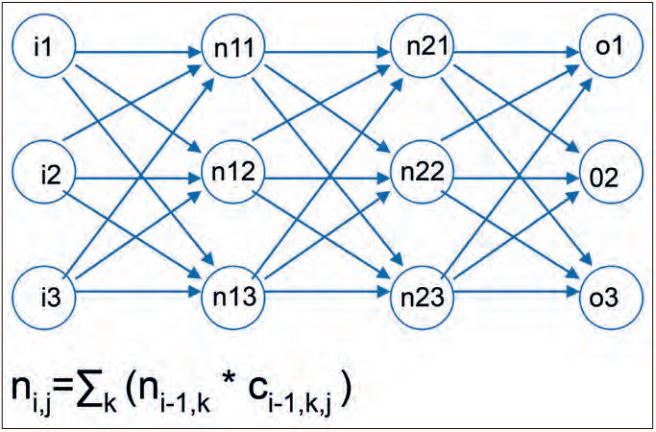
Abb. 3: Neuronales Netz und Berechnungsvorschrift
Lernen von Erklärungsmodellen
Ein wesentliches Problem beim Einsatz von KI-Methoden in eingebetteten Systemen ist, dass die Entscheidungsfindung für den Menschen oft intransparent und nicht nachvollziehbar ist. Einzelne Neuronen können nicht immer bestimmten Netzwerkfunktionen zugeordnet werden, was das Verhalten oft unerklärlich macht. Dieses Problem kommt bei Ende-zu-Ende-Ansätzen besonders zum Tragen: Wenn das selbstfahrende Auto plötzlich bremst, weiß der Passagier nicht, ob dies auf eine Fehlklassifikation eines Stoppschildes oder auf sonstige Ursachen zurückzuführen ist.
In neueren Arbeiten werden verschiedene Ansätze beschrieben, die Erklärbarkeit des durch das ML-System gelernten Verhaltens zu verbessern. Zum Beispiel lassen sich bei visueller Objekterkennung Regionen in den Kamerabildern hervorheben, die einen besonders starken Einfluss auf die Ausgabe des neuronalen Netzes haben (siehe Abbildung 4). Auf diese Weise lässt sich das Netz gegen bestimmte Typen von Angriffen absichern.

Abb. 4: Straßenszene mit markierten Entscheidungsregionen
Dieses Problem kann aber auch derart angegangen werden, dass das Netz als Ergebnis nicht nur eine Klassifikation erlernt, sondern auch die wesentlichen Parameter eines Modells der Steuerfunktion. Dadurch lässt sich das Verhalten nachvollziehbar gestalten, und Abweichungen vom Normalverhalten können auch während der Laufzeit erkannt werden.
„Sicherheitskäfig“-Architekturmodelle
Eine entscheidende Stärke von lernenden Systemen ist, dass sie sich zur Laufzeit weiter verbessern können, sofern das Lernen aus neuen Erfahrungen zugelassen wird. Im Falle eines neuronalen Netzes umfasst eine Lernaktualisierung unter anderem die Verarbeitung einer gegebenen Menge an Datenpunkten (z. B. Kamerabildern), die Berechnung des Ausgabefehlers gemäß der eingesetzten Bewertungsfunktion (z. B. Korrektheit der Klassifikation) und die Veränderung der Kantengewichte in Richtung des absteigenden Fehlergradienten.
Es existieren unterschiedliche Konzepte zur Verteilung von Lernaktualisierungen: in der Entwicklungsabteilung (nur vollständig trainierte Netze werden ausgeliefert), im Service-Zentrum (regelmäßige Aktualisierung durch den Hersteller) oder im Einsatz beim Kunden (kontinuierliches Lernen im Betrieb). Aktualisierendes oder kontinuierliches Lernen ist derzeit für sicherheitsrelevante Funktionen unzulässig, da Software, die sich von selbst verändert, bislang nicht hinreichend validiert werden kann.
Eine Methode zur Laufzeitabsicherung, Laufzeitverifikation und -qualitätssicherung besteht in der Realisierung eines „Sicherheitskäfig“-Architekturmodells, mit dem sich Eingangsdaten zur Laufzeit dahin gehend analysieren lassen, sodass sichere und unsichere Szenarien identifiziert werden und unterschiedlich behandelt werden können. So können unsichere Szenarien beispielsweise nur durch klassische Softwarelösungen umgesetzt oder durch solche gesondert abgesichert werden.
Für unser Beispiel der kamerabasierten Objekterkennung beim autonomen Fahren bedeutet das, dass zum Beispiel bei Autobahnfahrten das Ein- und Ausfädeln sowie das Durchfahren von Baustellen in einem anderen Modus erfolgt als das eigentliche Autobahnfahren.
Abbildung 5 zeigt die Unterscheidung zwischen sicheren und unsicheren Szenarien, wie diese auch in der SOTIF (Safety Of The Intended Functionality) nach ISO/PAS 21448:2019 definiert ist.
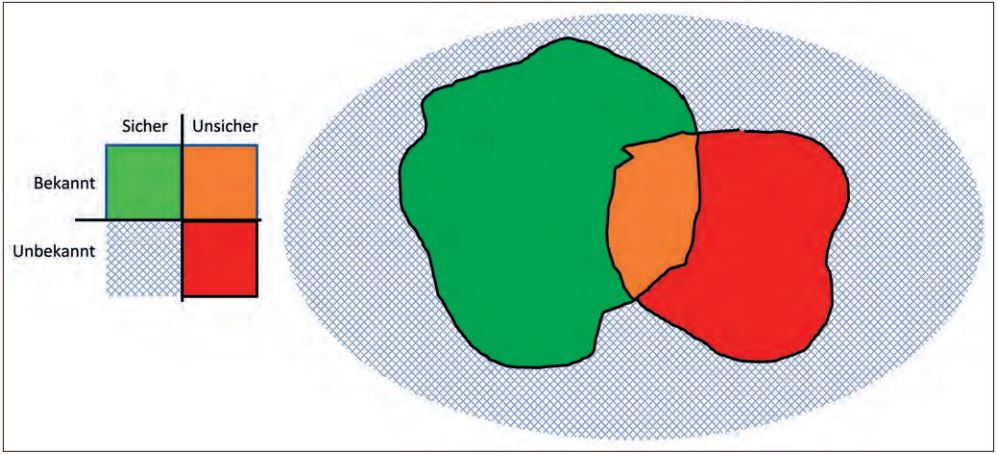
Abb. 5: Identifikation sicherer und unsicherer Szenarien nach SOTIF
Safety-Supervisor
Ein weitergehendes Konzept, um KI-Systeme auch in sicherheitskritischen Bereichen einzusetzen, besteht darin, die Entscheidungen kontinuierlich und adaptiv zu überwachen.
Es existieren verschiedene Online-Monitoring-Verfahren für kollaborative eingebettete Systeme, welche mögliche Probleme bereits vor deren Eintreten identifizieren können. Dieses Online-Monitoring von Modellen zur Laufzeit basiert jedoch auf einer klassischen temporallogischen Spezifikation des Steuerverhaltens und ist deshalb für KI-Systeme nicht unmittelbar geeignet.
Mit einer approximativen Spezifikation der Ziele von KI-Algorithmen lässt sich ein Safety-Supervisor ableiten, der auch für die KI-Komponenten die entsprechenden Modelle des Systemverhaltens zur Laufzeit automatisch überwacht. Mit diesem Ansatz ist es möglich, auch veränderliche Steuerfunktionalitäten eines KI-Systems zur Laufzeit zu garantieren und es somit auch in sicherheitsrelevanten Bereichen einzusetzen. Die Bremssteuerung „lernt“ also mit der Zeit, der kamerabasierten Verkehrsschilderkennung „zu vertrauen“.
Für die Umsetzung eines solchen Verfahrens werden allerdings neue Spezifikationsverfahren und Monitoring-Algorithmen benötigt, die derzeit noch Gegenstand der Forschung sind.
Fazit
Zusammenfassend lässt sich sagen, dass der Einsatz von maschinellem Lernen im Kontext eingebetteter Systeme, verglichen mit anderen Anwendungsfeldern, viele neue Möglichkeiten bietet, aber auch eine Reihe neuer Herausforderungen an die Qualitätssicherung stellt. Absicherungsmaßnahmen müssen einerseits die technischen Eigenschaften und Besonderheiten neuronaler Netze berücksichtigen. Die wichtigsten haben wir in diesem Text zusammengestellt.
Qualitätssicherung muss sich darüber hinaus mit der Kritikalität, Komplexität und Dynamik neuer Anwendungsfälle auseinandersetzen, die durch den Einsatz neuronaler Netze erst für die Automatisierung erschlossen werden. Hierbei handelt es sich um Anwendungsfälle in offenen Umgebungen, die bisher durch Menschen durchgeführt und überwacht wurden und aufgrund ihrer Komplexität einer Automatisierung beziehungsweise Formalisierung nicht zugänglich waren.
Ein Beispiel ist etwa die kamerabasierte Fußgängererkennung in einem hochautomatisierten Fahrzeug. Setzt man neuronale Netze für solche Aufgaben ein, ist es naheliegend, KI-Verfahren auch im Rahmen der Qualitätssicherung zu verwenden, um Simulationsund Umgebungsmodelle in ausreichender Komplexität zur Verfügung stellen zu können.
Es bleibt dann allerdings zu klären, wie diese Modelle selbst wiederum qualitätsgesichert werden.









