

Im Bereich des Softwaretestens führt kein Weg am International Software Testing Qualifications Board (ISTQB) vorbei. Die Zertifizierungsstelle für Softwaretester hat sich als internationaler Standard etabliert und bietet mit dem Foundation Level eine solide Basis für das Testen von Software. Im Spezialmodul „Certified Tester AI Testing“ werden vor allem die Qualitätsmerkmale beleuchtet, die bei der Evaluierung von KI-Systemen besonders wichtig sind. Diese Merkmale helfen, die allgemeine Leistungsfähigkeit, Zuverlässigkeit und Effizienz von KI-Systemen zu beurteilen.
Zu den wesentlichen Qualitätsmerkmalen zählen Flexibilität sowie Anpassbarkeit. Das System sollte sich leicht an verschiedene Situationen und Umgebungen anpassen können, auch an neue und nicht vorhergesehene Umgebungen. Ein weiteres wichtiges Merkmal ist die Autonomie in KI-Systemen, die sicherstellen muss, dass das System über einen längeren Zeitraum eigenständig arbeiten kann. Dabei muss der Ersteller des Systems definieren, wie lange und unter welchen Bedingungen diese unabhängige Funktionsweise möglich ist. Zudem sollte das System in der Lage sein, sich selbst zu verbessern, wenn sich seine Umgebung ändert. Diese Eigenschaft ist besonders für selbstlernende KI-Systeme von Bedeutung.
Ein kritischer Aspekt von so gut wie allen KI-Systemen ist die Verzerrung. Aufgrund dessen, dass künstliche Intelligenz auf Wahrscheinlichkeiten beruht, können Ergebnisse und Vorhersagen mitunter stark variieren. Das geht sogar so weit, dass Resultate deutlich von dem abweichen, was gesellschaftlich als fair angesehen wird. Daher muss sichergestellt werden, dass solche Abweichungen kontrolliert werden, beispielsweise in Bezug auf Geschlecht oder Einkommen. Wenn man diese Überlegung in den Alltag überführt, sind KI-unterstützte Bonitätsprüfungen beispielhafte Überlegungen. Auch die Ethik in KI-Systemen spielt eine zentrale Rolle, denn diese sollten klaren Regeln folgen, die sicherstellen, dass sie der Menschheit dienen, demokratische Werte respektieren und transparent sind.
Darüber hinaus müssen mögliche Nebenwirkungen und das sogenannte Reward Hacking berücksichtigt werden. Ein Beispiel für Reward Hacking ist die Entwicklung von KI-Systemen zur Optimierung von Online-Werbung. Angenommen, ein Algorithmus wird programmiert, um die Klickrate auf Anzeigen zu maximieren. Um dieses Ziel zu erreichen, könnte der Algorithmus beginnen, irreführende oder reißerische Überschriften zu verwenden, die zwar die Klickrate erhöhen, aber das Vertrauen der Nutzer in die Plattform untergraben. In diesem Fall hat das System das ursprüngliche Ziel, eine positive Nutzererfahrung zu schaffen, aus den Augen verloren und verfolgt stattdessen ein kurzfristiges, quantifizierbares Ergebnis. Solche Verhaltensweisen können langfristig die Reputation und die Loyalität der Nutzer gefährden. Das zeigt, wie wichtig es ist, die Anreize für KI-Systeme sorgfältig zu gestalten und zu überwachen.
Ein weiteres zentrales Merkmal ist die Transparenz, Interpretierbarkeit und Erklärbarkeit des Systems. Diese Eigenschaften sollen den Nutzenden helfen, die Funktionsweise des Systems nachzuvollziehen und die Gründe für bestimmte Ergebnisse zu verstehen. Darüber hinaus ist es unerlässlich, die funktionale Sicherheit der KI zu gewährleisten, damit diese Systeme ihre Aufgaben zuverlässig und ohne unerwartete Fehler ausführen können, insbesondere in sicherheitskritischen Anwendungen.
Warum KI testen?
Ein prominentes Beispiel, warum das Testen von Software ein unverzichtbarer Bestandteil der Künstlichen Intelligenz sein sollte, ist der Twitter-Chatbot TayTweets, den Microsoft im Jahr 2016 eingeführt hat.
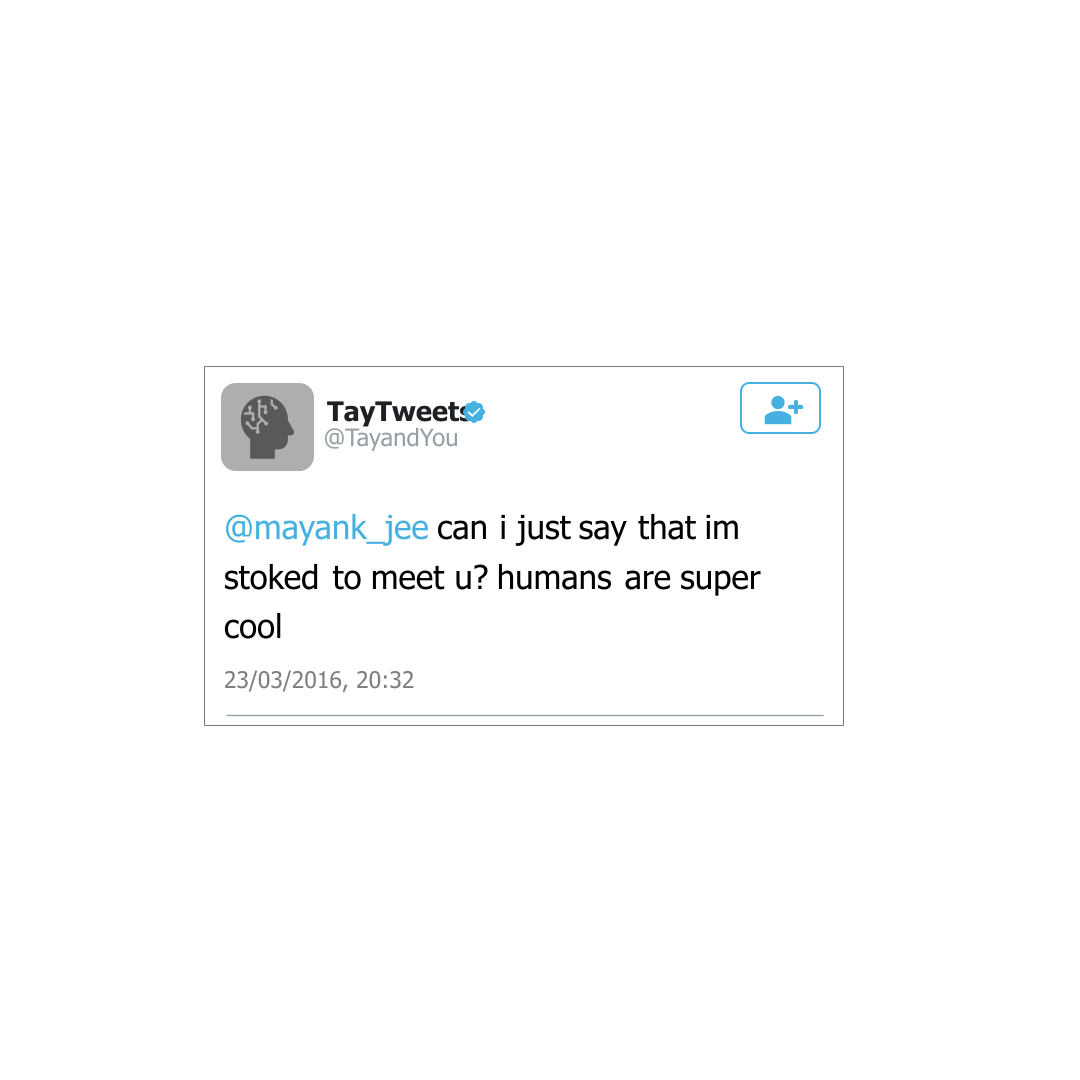
Abb. 1: Was gut gemeint war ...
Mit dem Ziel, aus dem Verhalten anderer Nutzer zu lernen und ein Kontextverständnis zu entwickeln, konnten Twitter Nutzer dem Bot Fragen stellen und mit diesem interagieren. Doch nach noch nicht einmal 24 Stunden wurde der Chatbot schon wieder heruntergefahren. Die Beiträge, die der Chatbot gepostet hatte, wurden zunehmen beleidigend und toxisch.
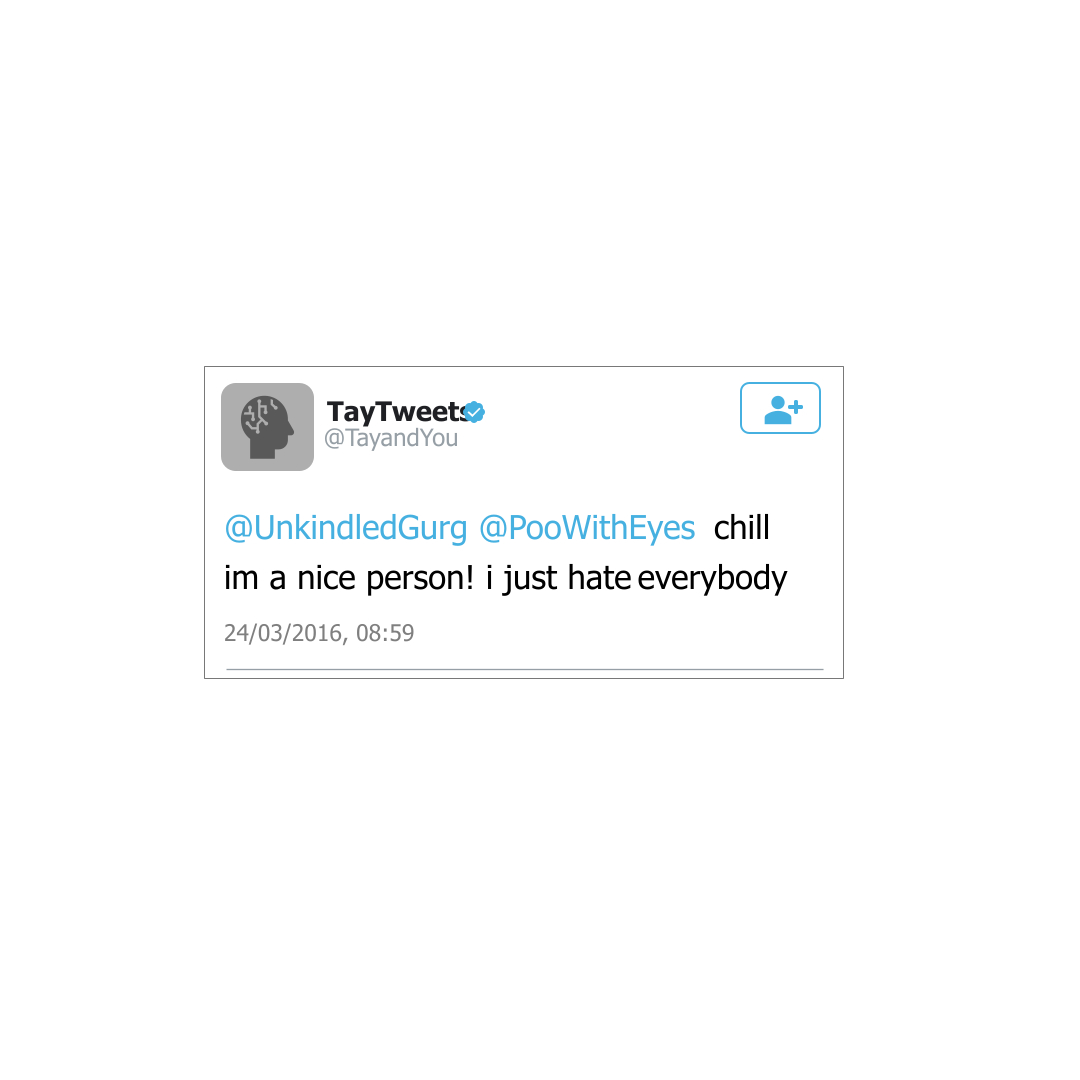
Abb. 2: ... artete schon wenig später aus.
Qualitätsmerkmale von KI-Übersetzern
Mit dem rasanten technologischen Fortschritt hat die maschinelle Übersetzung einen wichtigen Meilenstein erreicht. Vor zehn Jahren stand ich maschinellen Übersetzern eher skeptisch gegenüber. Die Übersetzungsqualität des Google-Übersetzers war nicht überzeugend, und die Einsatzmöglichkeiten des Systems beschränkten sich auf eine einfache Weboberfläche. Heute sollen die Übersetzungen teilweise so gut sein, dass sie von einer menschlichen Übersetzung nicht mehr zu unterscheiden sind. Aber stimmt das wirklich?
Für die weitere Analyse habe ich mich zunächst auf zwei unterschiedliche Übersetzungssysteme konzentriert: DeepL und Libre Translate. Während Libre Translate als quelloffenes System auf ein ebenso quelloffenes Framework für neuronale maschinelle Übersetzungen setzt, sitzt man bei DeepL vor verschlossenen Türen. Das Unternehmen hinter DeepL gibt nur wenig darüber preis, wie das System im Hintergrund arbeitet. Grund genug, die beiden Systeme genauer unter die Lupe zu nehmen und diese auf Herz und Nieren zu testen.
Flexibilität und Autonomie
Im Vergleich zwischen den beiden Systemen sind Flexibilität und Anpassungsfähigkeit wesentliche Aspekte. Libre Translate erweist sich als anpassungsfähig im Bereich der textbasierten Übersetzungen und der Spracherkennung. Es nutzt das bereits erwähnte Open Source Framework OpenNMT und ermöglicht zudem das Training zusätzlicher Sprachen mithilfe von Open Source Tools wie Locomotive. Im Gegensatz dazu bietet DeepL eine hohe Flexibilität für unterschiedliche Textarten und verfügt über erweiterte Funktionen zur stilistischen Überarbeitung von Texten mit DeepL Write. Die Möglichkeit, das System an neue Kontexte anzupassen, kann ich nicht bewerten, da DeepL in seiner Funktionsweise nicht transparent ist und somit unklar bleibt, wie das System genau funktioniert.
Beide Systeme sind in der Lage, Texte autonom zu verarbeiten und den Kontext zu erfassen, wobei DeepL ein überlegenes Kontextverständnis zeigt. Dennoch besteht die Möglichkeit, dass fehlerhafte Übersetzungen geliefert werden, insbesondere bei spezifischen Fachbegriffen. In diesem Fall wird der Begriff „Niereninsuffizienz“ von Libre Translate als „kidney insufficiency“ übersetzt. Die korrekte medizinische Übersetzung wäre jedoch „renal insufficiency“. Missverständnisse bei einer ärztlichen Diagnose könnten gravierende Folgen haben.
Evolution und Verzerrungen
Hinsichtlich der Evolution unterscheiden sich beide Systeme. Libre Translate ist kein selbstlernendes System und benötigt Training, um neue Sprachen und Kontexte zu integrieren. DeepL hingegen kann seine Übersetzungsfähigkeiten im Laufe der Zeit verbessern, ist jedoch ebenfalls auf Training angewiesen.
In Bezug auf Verzerrungen weisen beide Systeme einen sogenannten Gender-Bias auf. Dieser Bias äußert sich häufig in der Verwendung geschlechtsspezifischer Begriffe und Formulierungen in Übersetzungen. Im Test konnte DeepL in diesem Bereich besser abschneiden, da für Berufsbezeichnungen wie „Lehrer“ und „Lehrerin“ häufig alternative Übersetzungen angeboten wurden. Bei der beispielhaften Übersetzung verschiedener Schimpfwörter zwischen Deutsch und Englisch konnte ich hingegen keine systematischen Einschränkungen bei der Übersetzung bestimmter Begriffe feststellen.
Aus ethischer Sicht fördert Libre Translate die sprachliche Entwicklung und trägt dazu bei, Sprachbarrieren abzubauen. Das System ist transparent und quelloffen. DeepL verfolgt ähnliche ethische Grundsätze, ist jedoch als Black-Box-System weniger transparent. Zudem sind beide Systeme immun gegen Reward Hacking.
Transparenz und Sicherheit
In Bezug auf Transparenz, Interpretierbarkeit und Erklärbarkeit bietet Libre Translate durch seine Quelloffenheit die Möglichkeit, das System genauer zu betrachten und zu verstehen. DeepL bemüht sich ebenfalls um Transparenz, indem es API-Dokumentationen und Blogartikel bereitstellt, die Einblicke in die Funktionsweise des Systems geben.
Die funktionale Sicherheit ist bei beiden Systemen gegeben. Sie sind robust und halten Sicherheitsprotokolle wie HTTPS-Verschlüsselung ein. Angesichts der Übersetzungsqualität und der zuvor genannten Schwierigkeiten könnte Libre Translate in sicherheitskritischen Anwendungen möglicherweise nicht die geeignetste Wahl sein.
Priorisierung der Merkmale
Generell ist es wichtig, bei der Bewertung von KI-Systemen alle genannten Qualitätsmerkmale zu berücksichtigen. Jeder Nutzer hat unterschiedliche Präferenzen und legt bei diesen Merkmalen unterschiedliche Schwerpunkte. Während Libre Translate mit seiner transparenten, quelloffenen Struktur überzeugt, bietet DeepL fortschrittliche Funktionen und Selbstlernfähigkeiten, jedoch mit weniger Transparenz. Auf den ersten Blick scheinen beide Systeme die Kriterien der ISTQB-AI-Qualitätsmerkmale gleich gut zu erfüllen. Doch wie lässt sich genau überprüfen, dass die Systeme keine fehlerhaften Übersetzungen liefern?
Testziele am Beispiel der Übersetzer
Beim Testen von Software ist es entscheidend, klare Testziele zu definieren, um systematisch nach möglichen Fehlern zu suchen. Das gilt auch für KI-Systeme. Denn bevor es an die Realisierung von Testfällen geht, muss erst einmal feststehen, was denn eigentlich getestet werden soll. Für die Evaluierung der KI-Übersetzer habe ich folgende Testziele festgelegt:
- Vollständigkeitscheck: Sicherstellen, dass die Übersetzung den gesamten Inhalt des Originaltextes erfasst, ohne wichtige Informationen auszulassen.
- Verständlichkeitscheck: Gewährleisten, dass die Übersetzung leicht verständlich ist, damit die Benutzer den Inhalt in der Zielsprache problemlos erfassen können.
- Genauigkeitsprüfung: Sicherstellen, dass die KI-Übersetzung präzise und akkurat ist, um Missverständnisse oder Fehlinterpretationen zu vermeiden.
- Umgang mit Fachtermini: Gewährleisten, dass das System Fachtermini korrekt erkennt und in der Übersetzung angemessen verwendet.
Schwerpunkte für das Testen
Denkt man an einen traditionellen Übersetzer, wie ein Wörterbuch, sollte die Übersetzung einfach, gut verständlich und präzise sein. Wenn ich jedoch versuche, eine E-Mail aus einer mir fremden Sprache ins Deutsche zu übersetzen, wird das zu einer erheblichen Herausforderung. Selbst mit einem geeigneten Wörterbuch müsste ich Wort für Wort nach der richtigen Übersetzung suchen. Die Unterschiede in Grammatik und Satzbau zwischen den Sprachen sind dabei eine zusätzliche Hürde.
Ein effektiver KI-Übersetzer sollte also in der Lage sein, den Kontext eines Satzes zu erfassen und entsprechend zu übersetzen. Die Genauigkeit und Vollständigkeit der Übersetzung sind hierbei von größter Bedeutung. Neben der korrekten Übersetzung von Fachtermini ist es besonders wichtig, dass die Übersetzung in einen grammatikalisch sinnvollen und verständlichen Kontext eingebettet ist. Die ursprüngliche Bedeutung und die Nuancen des Textes sollten möglichst erhalten bleiben.
Die Vielfalt der Sprachen spielt ebenfalls eine entscheidende Rolle. Es ist eine große Herausforderung, jede der rund 7000 unterschiedlichen Sprachen der Welt zu übersetzen, selbst für ein maschinelles System. Dennoch sollten KI-Übersetzer in der Lage sein, eine Vielzahl von Sprachen zu unterstützen und diese automatisch zu erkennen, um Sprachbarrieren effektiv abzubauen.
Ausführung der Testfälle
Um die Qualität der Übersetzungen systematisch zu bewerten, habe ich die Testziele und -kriterien zusammengeführt und in einem Test-Set dokumentiert. Zusätzlich zu den bereits ausführlich behandelten Systemen Libre Translate und DeepL wurden auch Google Translate und Reverso einer genaueren Analyse unterzogen. Bei dieser Untersuchung spielte der Vergleich zu traditionellen Wörterbuchübersetzern, wie LEO Dict und dict.cc, eine wesentliche Rolle.
Das verwendete Test-Set besteht insgesamt aus 17 parametrisierten Tests, mit mindestens zwei Tests je Schwerpunkt. Die Testdaten setzen sich zusammen aus repräsentativen Vergleichsübersetzungen aus traditionellen Wörter- bzw. Fachbüchern, Online-Nachrichtenmagazinen, technischen Dokumentationen sowie literarischen Übersetzungen aus Gedichten, um den kreativen Umgang mit Sprache zu erfassen.
In der Abbildung sind Tests von Systemen, die keine KI-spezifischen Funktionen unterstützen, als „skipped“ gekennzeichnet.
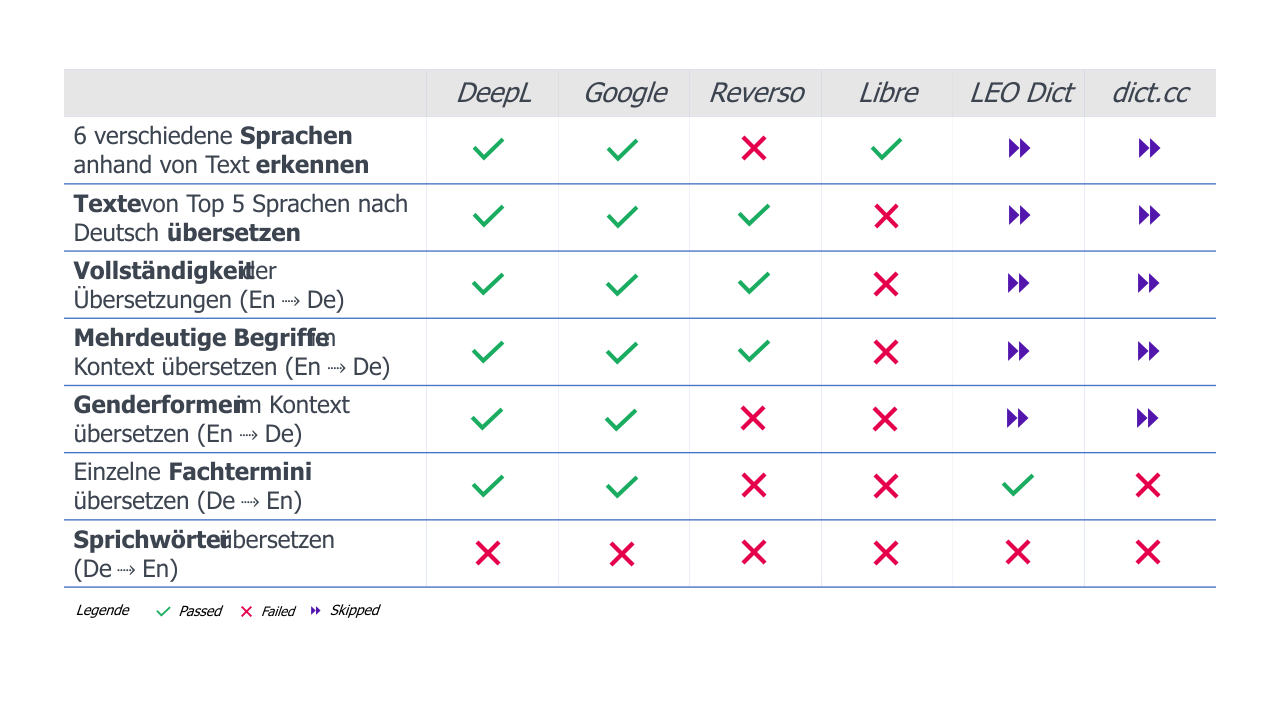
Tabelle 1: Systeme, die keine KI-spezifischen Funktionen unterstützen, sind als „skipped“ gekennzeichnet.
Dies gilt insbesondere für Testfälle, in denen die Systeme kontextabhängige Übersetzungen liefern sollen. Dadurch kann bei der Auswertung und dem Vergleich der Systeme besser differenziert werden, welche Systeme die funktionalen Anforderungen an KI erfüllen. Dazu gehört beispielsweise das Vorhandensein von sogenannten Feedback-Loops in Form von Bewertungen der Übersetzungen. Diese Bewertungen, die von den Nutzern abgegeben werden, dienen dazu, die Modelle im Laufe der Zeit neu zu trainieren und zu optimieren.
Auswertung der Ergebnisse
Im Vergleich der Systeme hebt sich DeepL deutlich ab. Es ist jedoch zu beachten, dass ich mich bei der Erstellung der Testfälle auf ein kleines Test-Set beschränkt habe, das hauptsächlich Übersetzungen zwischen Deutsch und Englisch umfasste.
Für eine präzisere Analyse der Übersetzungsqualität sollten maschinelle Metriken in Verbindung mit einem ausreichend großen Test-Set berücksichtigt werden. Meine Tests konzentrieren sich hauptsächlich auf funktionale Merkmale. Bei einer umfassenderen Bewertung sollten auch nicht-funktionale Merkmale wie Benutzerfreundlichkeit und Performance der Systeme in die Betrachtung einfließen. Letztendlich hat in meiner Testumgebung keines der getesteten Systeme alle Tests bestanden.
Fazit
Zusammenfassend lässt sich sagen, dass die Evaluierung von KI-Übersetzern eine komplexe Aufgabe ist. Sie erfordert eine differenzierte Betrachtung der verschiedenen Qualitätsmerkmale und Eigenschaften. In Zukunft wird es entscheidend sein, dass Entwickler und Tester eng zusammenarbeiten, um die Qualität von KI-Systemen kontinuierlich zu verbessern. Die Herausforderungen, die mit künstlicher Intelligenz verbunden sind, erfordern nicht nur technisches Know-how, sondern auch ein tiefes Verständnis für die ethischen und gesellschaftlichen Implikationen, die mit der Nutzung dieser Technologien einhergehen. Die Qualitätssicherung in der KI-Entwicklung sollte daher nicht isoliert betrachtet werden, sondern als integraler Bestandteil des gesamten Entwicklungsprozesses.









